Have a critical cron’d automated task? You’d like to be notified if something fails? With the ubiquity of smartphones, you can notice an error right away and take action. Wow, someone wrote to me! It’s from someone named “mdadm”. Must be spam again!
Computers sending emails for various purposes is nothing new. I have a couple of critical cron jobs on my home computer; syncing the family photos to my remote server, backing up the said remote server to my local computer, etc. These are all tasks that are defined in the daily crontab, and without a proper or any alerting system, something can go wrong and you can really find yourself in a bind if it turns out the backup procedure died months ago because the ssh key changed or something. You can either check the backup or automated task every single day to make sure nothing went wrong, or you can setup a robust alerting system that will send you an email if something goes wrong. This is not the only use case, Mdadm can also send you an email if a disk drops from a RAID array etc.
Setting up a Gmail relay system with Postfix
Installing and managing an email service is difficult, and you have to contend with all sorts of issues, is your server blacklisted, do you have the appropriate SPF records, is your IP reverse resolvable to the domain name etc, etc. Most of these requirements are difficult or impossible with a simple home computer behind a router without an FQDN. With the relay, you’ll be able to send an email without having to worry if it’ll end up in spam, or not delivered at all as it will be sent from a real Gmail account. Luckily, it’s extremely simple to set it up:
Allow “less secure” apps access your new gmail account. Don’t be fooled by how they’re calling it, we’ll be having full encryption for email transfer.
Setup Postfix.
I’ll keep the Postfix related setup high level only:
Install Postfix with your package manager and select “Internet site”
Edit /etc/postfix/sasl_passwd and add:
[smtp.gmail.com]:587 username@gmail.com:PASSWORD
Chmod /etc/postfix/sasl_passwd to 600
At the end of /etc/postfix/main.cf add:
relayhost = [smtp.gmail.com]:587 # the relayhost variable is empty by default, just fill in the rest
smtp_use_tls = yes
smtp_sasl_auth_enable = yes
smtp_sasl_security_options =
smtp_sasl_password_maps = hash:/etc/postfix/sasl_passwd
smtp_tls_CAfile = /etc/ssl/certs/ca-certificates.crt
Use postmap to hash and compile the contents of the sasl_password file:
# postmap /etc/postfix/sasl_passwd
Restart the postfix service
Your computer should now be able to send emails. Test with a little bit of here document magic:
If everything went fine, you should be getting the email promptly from your new gmail account. I haven’t tried with other email providers, but it should all be pretty much the same.
Usage example
Now that you have a working relay, it’s time to put it to good use. Here is a simple template script with two key functions that can be sourced through Bash so you can use it within other scripts without having to copy & paste it around.
#!/bin/bash
# Global variables
NAME=$(basename "$0")
LOG=/var/log/"$NAME".log
EMAIL=youremail@whatever.com
LOCKFILE=/tmp/"$NAME".lock
HOST=$(hostname -s)
# All STDERR is appended to $LOG
exec 2>>$LOG
# An alert function if the locking fails
function lock_failure {
mail -s "Instance of "$0" is already running on $HOST" $EMAIL << EOF
Instance of "$0" already running on $HOST. Locking failed.
EOF
exit 1
}
# An alert function if something goes wrong in the main procedure
function failure_alert {
mail -s "An error has occured with "$0" on $HOST" $EMAIL << EOF
An error has occured with "$0" on $HOST. Procedure failed. Please check "$LOG"
EOF
exit 1
}
function procedure {
# If file locking with FD 9 fails, lock_failure is invoked
(
flock -n 9 || lock_failure
(
# The entire procedure is started in a subshell with set -e. If a command fails
# the subshell will return a non-zero exit status and will trigger failure_alert
set -e
date >> $LOG
command 1
command 2
[...]
)
if [ $? != 0 ]; then
failure_alert
fi
) 9>$LOCKFILE
}
function main {
procedure
}
main
flock(1) is used to make sure there is only one instance of the script running, and we’re checking the exit status of the commands. If you don’t need instance locking, you can simply forego the lock_failure function. The actual work is contained in another subshell which is terminated if any of the commands in the chain fail and sends an email advising you to check $LOG.
Conclusion
A lot of Linux services like Mdadm or S.M.A.R.T. have a feature to send emails if something goes wrong. For example, I set it up to send me an email if a drive fails inside my RAID 1 array, I just had to enter my email address in a variable called MAILADDR in the mdadm.conf file. A couple of days later, I received an email at 7 AM; ooooh someone emailed me. I had a rude awakening, it was Mr. Mdadm saying that I have a degraded array. It turned out to be the SATA cabling that was at fault, but still. This could have gone unnoticed for who knows how long and if the other disk from the RAID 1 failed later on, I could have had serious data loss. If you want to keep your data long term you can’t take any chances, you need to know if your RAID has blown up and not rely on yourself to check it out periodically, you won’t, you can’t, that’s why we automate.
Be careful when you write these programs. If your script is buggy and starts sending a lot of emails at once for no good reason, Gmail will block your ass faster than you can say “Linux rules!” If you’re blocked by Gmail, you might miss an important email from your computer.
In a comment on my answer to a StackOverflow question about callbacks in Rust, the commenter asked why it is necessary to specify 'static lifetime when boxing closures. The code in the answer looks similar to this:
It seems redundant to specify the lifetime of a boxed object that we already own. In other places when we create a Box<T>, we don’t need to add 'static to T’s trait bounds. But without the 'static bound the code fails to compile, complaining that “the parameter type CB may not live long enough.” This is a strange error – normally the borrow checker complains of an object not living long enough, but here it specifically refers to the type.
Let’s say Processor::set_callback compiled without the lifetime trait on Fn(). In that case the following usage would be legal as well:
fn crash_rust() {
let mut p = Processor::new();
{
let s = "hi".to_string();
p.set_callback(|| println!("{}", s.len()));
}
// access to destroyed "s"!
p.invoke();
}
When analyzing set_callback, Rust notices that the returned box could easily outlive the data referenced by the CB closure and requires a harder lifetime bound, even helpfully suggesting 'static as a safe choice. If we add 'static to the bound of CB, set_callback compiles, but crash_rust predictably doesn’t. In case the desire was not to actually crash Rust, it is easy to fix the closure simply by adding move in front of it closure, as is is again helpfully suggested by the compiler. Moving s into the closure makes the closure own it, and it will not be destroyed for as long as the closure is kept alive.
This also explains the error message – it is not c that may not live long enough, it is the references captured by the arbitrary CB closure type. The 'static bound ensures the closure is only allowed to refer to static data which by definition outlives everything. The downside is that it becomes impossible for the closure to refer to any non-static data, even one that outlives Processor. Fixing the closure by moving all captured values inside it is not always possible, sometimes we want the closure to capture by reference because we also need the value elsewhere. For example, we would like the following to compile:
// safe but currently disallowed
{
let s = "hi".to_string();
let mut p = Processor::new();
p.set_callback(|| println!("later {}", s.len()));
println!("sooner: {}", s.len());
// safe - "s" lives longer than "p"
p.invoke();
}
Rust makes it possible to pin the lifetime to one of a specific object. Using this definition of Processor:
struct Processor<'a> {
// the boxed closure is free to reference any data that
// doesn't outlive this Processor instance
callback: Box<dyn 'a + Fn()>,
}
impl<'a> Processor<'a> {
fn new() -> Processor<'a> {
Processor { callback: Box::new(|| ()) }
}
fn set_callback<CB: 'a + Fn()>(&mut self, c: CB) {
self.callback = Box::new(c);
}
fn invoke(&self) {
(self.callback)();
}
}
…allows the safe code to compile, while still disallowing crash_rust.
Nema više Potato Housea. Vlasnik tužno stoji ispred lokala i pozdravlja se sa stalnim mušterijama.
Za one koji ne znaju, Potato House je bio fini bistro generalno ruskog stila u kojem su se mogle dobiti odlične guste juhe, npr. boršč, kao i još nekolicina pomno probranih jela. Njihov specijalitet bio je kuhani krumpir izdubljen, na licu mjesta obogaćen smjesom maslaca i krumpira, kao i umacima s nekoliko okusa (indijski, chilli con carne, kikiriki+piletina, ćuftice…). Nazvati ih restoranom brze hrane bilo bi tehnički ispravno, jer tamo bi hrana brzo stigla, ali potpuno promašeno po kvaliteti, koja je bila daleko iznad onog što se normalno podrazumijeva pod fast foodom. I sve to po vrlo prihvatljivim cijenama.
Priča čovjek da zatvara jer “nakon tri godine više ne može”. I nakon svih horor priča o besmislenim propisima, uspjelo me šokirati da “objekt koji nema vlastiti WC mora imati isključivo visoke stolove”. Ha? “Time si mi diskriminirao niže ljude, starce, djecu, invalide”, nastavlja ogorčeno. “I zašto moram plaćati turističkoj komori, naknadu za šume? Kakve to ima veze sa mnom?” Pa problemi s osobljem, skup najam lokala, opće nerazumijevanje na svakom koraku.
“Puno lokala se danas otvara, ali ih se još više zatvara”, kaže, a to i sam vidim. Usprkos današnjem boomu restoranske ponude (ili baš zbog njega) u zadnjih mjesec-dva nestalo nekoliko meni dragih mjesta – “Kroštula” kod Cvjetnog, slastičarnica s vaflima u Masarykovoj, a evo sad i Potato House. A ni propast “Kiše”, čija se vlasnica također žalila na nemoguće propise, nije bila tako davno.
Nadam se da će boom zagrebačke restoranske ponude dovesti u biznis nove ljude, od kojih se neki možda i uspješno izbore s hrvatskom poslovnom klimom.
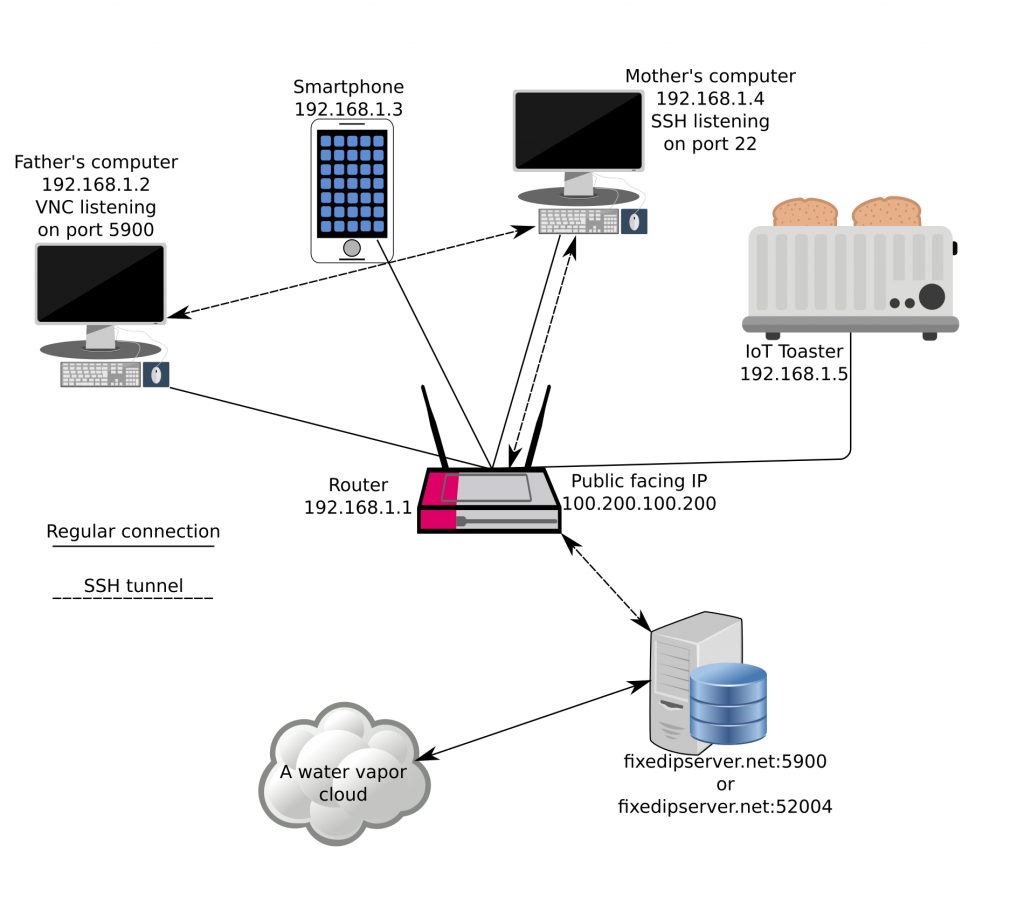
SSH can be more than a secure shell. It has a cornucopia of features and use cases, it’s mature, and extremely widely used. I’ll cover NAT busting today with SSH. Say your parents are behind a shitty ISP and an unstable connection, and your mother has Linux installed, while your father has Windows installed. His computer sometimes misbehaves, and you want to connect via VNC, but the shitty router of the shitty ISP has managed to mangle all the port forward configs and the dyndns script failed to update the IP because $REASONS. As with all NAT busting schemes, you’ll need a third computer somewhere connected to the internet with a fixed IP address.
What’s the problem?
Simply put, NAT (Network address translation) is a popular way to group many IP addresses (computers and various devices, phones on a local area network) into a public facing one. When you connect to a remote host, the router keeps track of individual requests. If your computer’s address is 192.168.1.4, the remote host can’t send data back to a private network across the internet. The response is sent back to the public IP address and a random port chosen by your home router, which is then forwarded to 192.168.1.4 from the router. This all works great for connecting to websites, game servers, and whatnot, but what if you want to connect from the outside to a specific computer inside a NAT-ed environment in a way that is robust and secure?
SSH to the rescue
I’ll first cover the steps how to perform NAT busting to get access to the hypothetical mother computer:
Create a user for that purpose on the server with the fixed IP. Use /bin/false as the user shell as an extra security measure.
Place the mother’s public SSH key in the user’s authorized_keys file for passwordless login.
You’ll need to put GatewayPorts yes and ClientAliveInterval 10 in the sshd config on the server and restart the SSH daemon. The ClientAliveInterval setting is very important, I’ll come back to it.
After this is done, we can proceed with setting up the actual tunnel:
$ ssh -fNg -R 52004:localhost:22 user@fixedipserver.net # On the mother's computer
$ ssh -p 52004 mother@fixedipserver.net # Connect to the mother's computer
"-f" switches ssh right to the background, "-N" is a switch to not execute any remote command, "-g" allows remote hosts to connect to local forwarded ports, and "-R" is here to specify the remote port, the IP on the local server, in our case localhost and local port, port:host:hostport. The "GatewayPorts yes" option is needed because SSH by default won’t allow to bind on anything other than 127.0.0.1, I guess this is a security feature. Basically, we have now exposed the port 22 of my mother’s computer and bound it to the 52004 port on fixedipserver.net so make sure that your dear mother’s SSH is properly secure, it would be best to disable password logins altogether if possible. The fixed IP server now acts as a bridge between you and the computer behind the NAT, and when you ssh to the port 52004 you’ll be expected to present the credentials of the mother’s computer, and not the fixed IP server. Nice, huh?
Wait a second Mr. Kitty, how exactly is this persistent?
It’s not. Two problems come to mind; the mother reboots the computer and poof, the tunnel is gone, or the shitty ISP router reconnects. Enter Autossh, it comes packaged with most newer distros. The author says: “autossh is a program to start a copy of ssh and monitor it, restarting it as necessary should it die or stop passing traffic.”
Wow, just what we need! We’ll just fire it up like so:
Please note that you need to enable GatewayPorts yes on the mother’s computer as well if you want to route traffic like this. No need for autossh for these temporary interventions, and it’s probably a bad idea to have port 5900 open to the public all the time.
Autossh tuning for an even more robust tunnel
Autossh with its default settings is probably good enough for most cases. Certain ISP routers have a very nasty habit of killing idle connections. No communications on an open TCP connection for 2 minutes? Drop it like a hot potato without letting anyone know. The computer behind the router is convinced the connection is still alive, but if it tries to communicate via that open connection all the packets seemingly go into a black hole and the network stack takes a while to realize what’s going on. Now, let’s get back to ClientAliveInterval 10 and why it’s so important:
This is all fine and dandy, but a true sysadmin will always test his assumptions and procedures. I setup a simple autossh tunnel, browsed to my DD-WRT web GUI and reset the modem to simulate an internet crash. The modem quickly recovered, the internet connection was restored and after a few minutes, whoops:
$ telnet fixedipserver.net 52004
Trying 100.100.100.100...
Connected to fixedipserver.net.
Escape character is '^]'.
Not good, where the hell is “SSH-2.0-OpenSSH_7.2p2 Ubuntu-4ubuntu2.1” that I usually get? I only managed to connect to the dangling port on the server that leads nowhere. The connection server-side is disconnected after 30 seconds at these settings, however under slightly different conditions while I was testing the port 52004 is still bound by the old connection the ssh daemon hasn’t cleaned up yet causing ssh to fail to create a tunnel because the server says that port 52004 is busy. Fine, fair enough, however the big problem is that ssh will not exit because of this when trying to establish a tunnel. It’s a warning only and the process is still up & running. As far as autossh is concerned all is dandy. Well, it’s not! With the -o "ExitOnForwardFailure yes" we force that this kind of error makes ssh exit with a non-zero exit status and makes autossh do its intended purpose; try to reconnect again and again. The environment variable AUTOSSH_POLL makes it do internal checks of the ssh process a little bit more frequently.
The -M 0 disables autossh’s builtin monitoring using echo and relying on SSH’s very own ServerAliveInterval 15 which probes the connection every 15 seconds, and ServerAliveCountMax 2 is the number of tries until SSH will kill off the connection if the connection is down. In conjunction with ServerAliveInterval 15 assuming the connection was reset, ssh will again exit with a nasty non-zero exit status which will force autossh to react. It is an absolutely crucial setting to achieve true high availability with a disconnecty modem. The idea is to get an up & running tunnel as soon as it’s theoretically possible, IE, the end client has a fully working internet connection once again. Without the echo method we achieve a pretty simple and robust setup in the end. If you connect to fixedipserver.net port 5900 it will route you to the father’s computer over the mother’s computer. If you connect to port 52004 you will get the mother’s ssh service, port 22.
Set the two following options in the sshd config and reload the daemon:
GatewayPorts yes
ClientAliveInterval 10
We’ll need to set an environment variable before starting Autossh. You can use this as a reference for a simple script:
#!/bin/bash
REMOTE_PORT=40000 # The exposed port on the fixed IP server that you'll be connecting to
DESTINATION_HOST=localhost # Any host that is connectable from the computer initiating ssh/autossh can be set, be it a server inside the LAN, or a server on the internet, or localhost, it doesn't matter to SSH
LOCAL_PORT=22 # The destination port we want to have access to (port 22 - SSH in our example, can be anything, doesn't even need to be open)
export AUTOSSH_POLL=45
autossh -M 0 -o "ExitOnForwardFailure yes" -o "ServerAliveInterval 15" -o "ServerAliveCountMax 2" -fNg -R $REMOTE_PORT:$DESTINATION_HOST:$LOCAL_PORT user@fixedipserver.net
And finally, you can set a cronjob:
@reboot connect_script
Final thoughts
The robust tunnel part is really necessary if you have a mission critical server or client somewhere behind a flaky connection, whether you need it for pure ssh access or you need it for something like VNC or another service somewhere on the remote private network. Please keep in mind that any forwards you setup like this will be available from anywhere on our hypothetical fixedipserver.net server. Who knows what kind of vulnerabilities a service has, so firewall everything off on the server with the fixed IP. There is some good news though, if someone does hack into the remote machine via your open VNC port or whatever, you can rest assured in the knowledge that their traffic between the fixed IP server and your pwned service are safe with a state of the art encryption protocol provided by the wonderful Secure Shell.
An intriguing movie covering a coming-of-age sort of thing in New York City. Tracy (Lola Kirke) is an aspiring would-be writer having trouble fitting in at Barnard, so on her mother’s advice she contacts her soon to be step-sister Brooke (Greta Girwig). The movie doesn’t have the sort of predictability you would come to expect, the characters are likable, their relationships and dialogues interesting. Brooke wants to open up a restaurant which is also a hipster paradise, a place where you can hang around and talk, and of course order food, be able to trade etc. She goes a long way but needs some capital to get things started. She’s a smart and independent woman, but still realistically clueless, as we all are when we’re in our thirties. She goes to her ex to get him to invest in the new business, Tracy accompanies her because she really believes in Brooke and is sort of in love with her. There is no one to drive her but Tracy’s ex-crush and his new girlfriend. A mishmash of characters that somehow work together nicely.
The whole movie in the end is sort of depressing, but hey, that’s life. Greta Girwig is a really beautiful and talented actress, I’ll have to keep an eye out for this one. Definitely recommended.
Yes, there’s a female character in the movie too. An aesthetically pleasing sci-fi flick with a minimal cast and beautiful scenery. The starship Avalon is travelling at 0.5c towards a distant colony. The entire crew and its 5000 passengers are in deep stasis of some kind since the voyage to Homestead II takes about 120 years. Our protagonist Jim’s (Chris Pratt) stasis pod starts a reanimation sequence due to a very specific and unlikely event. The passengers are suppose to be reanimated some 4 months before arriving to the distant colony, but Jim is awaken some 88 years before the voyage ends.
There’s a lot of details in the movie, it’s a part of a new trend where the sci-fi film is realistic as possible. No FTL, no wormholing, no fancy SF shit, a ship like this is maybe possible within 10 generations, maybe. Jim sends a message back to home, but since they’re 30 years out already, it’d take approximately 17 years for the message to reach Earth and then it would have to catch up to the Avalon when they reply, so the earliest reply is in 55 years. Great, a lifetime spent in the bowels of a ship, but it’s not all so grim, he has an android bartender named Arthur (Michael Sheen) to keep him company, and has plenty of food. The movie has a weird melancholy attached to it, how everyone has a different reason for choosing such a strange life as by the time you reach the other world all your family and friends will have died. It’s the ultimate fresh start. Not going to spoil the movie further, surprisingly recommendable for a mainstream movie.
Now this movie is a particularly interesting take on the vampire genre by a director called Xen Cassavetes. An exquisitely fresh combination of erotic scenes, common vampire themes along with a narrative to explain and explore how an underground vampire society could co-exist with humans. Humans are still preyed upon for food, but is generally not done as the vampires are afraid their cover would be blown. The vampires drink animal blood and substitutes, live in lavish and remote houses where maids reside during the day to keep an eye out for their employers while they sleep and of course do housework. The maid in the movie has a rare genetic blood disorder which makes her completely unattractive to the vampires and that makes her very sought after.
The story begins where Paolo (the always lovable Milo Ventimigla) meets Djuna (Joséphine de La Baume), a hot vampire. They of course, fall in love and very soon proceed to have hot human-vampire sex. She’s shy at first because she has to reveal her true form and insists Paolo chains her to her bed so she can’t hurt him. She turns and the shackles are barely able to hold her sexy demonic form on the bed. This is a major turn on for Paolo who promptly unchains her and they have sex. Oh, she technically kills him in the process but it’s all right since he’s now a vampire. His senses are heightened, can’t stand the daylight and is always battling the urge to suck a human dry.
They’re a match made in heaven, all they have to do is fuck all night and be philosophical since Djuna has a very wealthy and influential vampire upper society friend who lets them use her fabulous house somewhere in the country. They got no jobs, no bills, very convenient for a love story. Their seemingly peaceful (un)life is disrupted when Djuna’s disturbed and of course hot vampire sister arrives, Mimi (Roxane Mesquida). The sisters are pretty ancient, hundreds of years or so and are always fighting. Mimi seems to resent the fact that Djuna turned a human as they swore they’d never do something like that. Mimi is a disruptive element to anyone that has anything to do with her and causes chaos for everyone. Her story line has a great ending, not gonna spoil that one for you.
In essence, a totally unheard of movie which I personally kind of liked. Definitely recommended if you don’t only favor movies with an ensemble cast or a strong and popular lead. Decent exploration of the vampire theme, actually pretty decent acting in a way, and a surprising amount of eroticism in it.
A collection of random edits of photos, some slight pixel rearrangements etc. I’d like to say that each picture represents something meaningful, but it doesn’t.
The wonders of the smartphone. For us tech savvy people the current modern variant of the smartphone is pretty neat. You can navigate across the globe with the maps, you can of course listen to music or watch films, take photos, view photos, surf the net, etc. As most parents, I too love to talk about my kid, and I like showing a couple of pics to friends.
In earlier posts I was talking about managing, keeping your collection safe, organized. What if you find yourself in the situation that you want to show a specific picture to someone? You can’t expect to have all the photos you’ve taken over various devices to be present on your smartphone. This seemed like a good idea actually, to have access to all of your pictures on the phone.
My wishlist:
The pics themselves be somewhere on the internet, or my home computer so I can connect via a dynamic DNS service.
The pictures are scaled and quality lowered, so I don’t spend a lot of mobile data viewing unnecessarily large photographs, ~100 KiB per picture or even less. It should be fine for a smartphone display.
It would be extremely nice if the whole thing is encrypted end to end.
Turns out there are a couple of solutions already present on the market. One of them is Plex. A cursory glance at the website seems to indicate that it has what I want. There were some issues, however. First off, it’s a totally closed, proprietary bullshit service. How does it work? Supposedly you install the Plex media server on your computer, and with a client on your smartphone you connect directly to your library of photos, videos and music on your PC. Someone even packaged it for Arch Linux. The entire package is over 130 MiB in size. Unfortunately, this service is a bit of an overkill for my requirements. It’s an entire platform for you to play your mostly pirated stuff from a remote location. Sure, that makes sense for some people, but all I need is a gallery viewer and to somehow fetch the photos over the internet.
My first thought was, do they even encrypt this traffic between the phone and your home computer? Of course they didn’t. They do now, but the encryption was implemented a couple of months ago. Seems they even pitched in for a wildcard SSL certificate of some sort. If it’s a wildcard certificate for their domains, that means they proxy the traffic somehow. But considering their track record with basic security, ie, having no encryption of any kind, I’m not so convinced they actually encrypt the entire stream from end to end. To be fair, they have to support a lot of shady devices, like TVs and such, and there’s no telling what kind of CAs do these devices have and what kind of limitations are imposed.
OK, so I gave up on Plex, there has to be some kind of simpler solution. I noticed that an app I was already using, QuickPic, has native support for Flickr, Picasa, some others, and Owncloud. I really don’t want to give all my photos to a nameless cloud provider, but Owncloud, now that’s something. I have a budget dedicated server in Paris, and I decided to give it a try. I won’t go into details on how to install Owncloud. I’m using the Nginx webserver with PHP-FPM. Since the server isn’t exactly mine, and I have issues with trusting private data to anyone, I decided to use a loopback device on the server with a bigass file, and encrypted it with cryptsetup and is mounted to serve as the data directory of Owncloud. This way, once the server is decommissioned or a disk fails, no one will be able to see the content from the Owncloud data directory.
I don’t really want to go into the Owncloud installation. It’s relatively simple, it supports MySQL, Postgresql, sqlite, needs a reasonably recent PHP version and a webserver like Apache, or Nginx. So all I had to do now is prepare the photos, so I can upload them. And once again, Linux comes to the rescue. First, I copied the entire library to somewhere so I can test out the recoding mechanism. All my photos are in an extremely simple hierarchy. YYYY-MM, so that’s 12 directories per year. So:
for i in * ; do (cd $i; mogrify -auto-orient -quality 55 *); done
After that it’s pretty much as you’d expect. Upload the photos via the Owncloud client for Linux which works pretty much Dropbox. Once it’s uploaded you can setup QuickPic on your android phone to connect to the Owncloud instance. And that’s it, you can now access your full photo collection, you’ll just have to periodically add new pictures into the mix. Keep in mind that Owncloud generates the thumbnails on the fly when QuickPic requests photos, which is pretty cool. It’s not blazing fast, but it’s acceptable. The thumbnails are then cached in the Owncloud’s data directory, meaning that it will be a lot faster the second time you view the same directory.
I’ve also setup a script that automatically recodes all the images I take from my digital camera and uploads it to the server. That way I can have access to all the latest photos, I can view them from anywhere. Everything is reasonably secure, under your control.
QuickPic is a great photo app for smartphones in general, not just for Owncloud used in this way.
Not sure what genre The Lobster belongs to, I’d say dystopian present, and no SF to be found. The movie is a wonderful blend of surreal exterior and interior shots, great camera work and angles, and an intrusive musical score that conveys the uneasy atmosphere throughout the movie.
The non spoiler synopsis:
Colin Farrell is David with a silly mustache, a man that is sent off to a hotel that is dedicated for pairing people up. If they fail to do so within the first 45 days, they are turned into an animal of their choosing. The only way to leave the hotel is either fall in love with someone, or simply by running away. Extending your stay in human form without falling in love is only possible by hunting down the people that have run away from the hotel and brought back to be turned into an animal.
Spoilers ahoy — The story
The story starts with David entering the hotel and having his expectations explained by a woman with a very creepy bureaucratic voice. He is accompanied by a dog that he reveals is his brother that “didn’t make it”, at the very same hotel. The movie continues to show the day to day lives of the hotel guests. Society expects them to fall in love with a person, doesn’t matter which gender. They need to prove their love is real, lest they suffer the consequences. The hotel staff is very strict and rigid. It is in societies’ best interest to pair people off, and the hotel is there for that purpose only. Masturbation is strictly prohibited on the hotel grounds. The female staff is arousing the male guests at regular intervals by grinding their crotch to achieve erection and then leaving them with a nasty case of blue balls and no masturbation as an option.
This is what I call cruel and unusual punishment
David sees a chance of pairing off with a woman that is notorious at the premises, as having the most days lined up, over 150 of them, as you get a day extension for each person you bring back to the hotel. The woman is completely heartless, stripped away of any emotions, but still even she has some interest in pairing and leaving the hotel. Some couples are given children to help them bond, and David in one instance adapts to the psychopath and becomes completely heartless, like kicking the little girl in the leg front of their guardians, because her new father has a limp so they’re more alike.
He completely changes for this person, but is still rattled when she outright kills his brother, the dog. She comes into the room and says she killed him by kicking him over and over and that he might still be alive. The frame then shows her leg which is dripping blood from kicking the poor dog incessantly. David simply shrugs it off and saying that it doesn’t matter. He goes to brush his teeth and sees the dog – his brother, lying in a pool of blood and with an open wound on the abdomen. David starts brushing his teeth, but breaks down in tears. The woman catches him weeping and is dragging him to the hotel manager, because he was lying, he DOES have feelings for something or someone, and they aren’t a match.
David eventually flees the hotel, and joins the loners, the people that choose to be alone and don’t want to be with someone. They also have very strict rules and punishments for those that become involved, for example is someone is caught kissing, they slice open the lips of both people and force them to kiss. At this point the movie sort of loses its momentum. There are a couple of scenes from the city, where everyone is openly and annoyingly together. People are stopped for random checks of their marriage certificates to prove they’re not alone and are checked for mud to make sure they’re not runaway loners around the city.
Why not an SF movie?
Everyone says that the movie is sci-fi, because of the dystopian future and the animal transformations. At no point in the movie is the transformation shown or adequately explained. Rumors are flying around the hotel of how it is done, but no one knows for sure. The movie is satire and criticism of our society, how little we sometimes ask questions. All the characters in the movie don’t really see that the hotel staff is abusive and their whole exploit is completely insane. I think the transformations are some sort of metaphor, the people are probably killed. The movie goes as far as to never really prove that the animals were human, and that their essence is somehow captured within the animal. One of the characters says that his mother was left by his father and that she was transformed into a wolf and sent off to a zoo. He went to the zoo as often as possible and gave raw meat to the wolves, as that is what wolves normally eat. He fell into the wolf pit one day and all of the wolves, save for two, came attacking him because and he claimed that one of the two wolves was his mother, he had no idea which. The animals obviously do not have any human left in them, or they’re completely unable to show it and if so, one has to wonder were they ever human at all, or are all the people from the hotel and the picked up loners are simply murdered and this wild story is being fed to them – again a metaphor of the modern world and our lulled existence within it.
Should you see it?
Yes, you should. The movie, despite the several shortcomings is visually great, has solid dialogue and narration. The movie in the end doesn’t explain how and why is society like this. I thought that it might be aliens or something but the movie really leaves it to your imagination. The Lobster isn’t mainstream and is probably unwatchable for a lot of people. I usually rate movies by how much I think about them in the days after watching them, this one has stuck for a while. Bad movies are forgotten as soon as they’re watched, good ones stick a while.
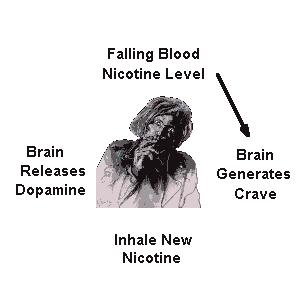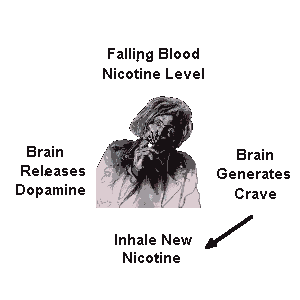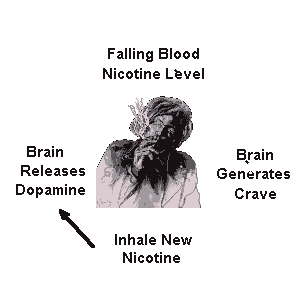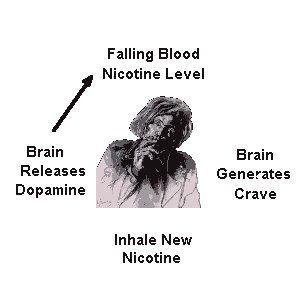
As you might imagine from the title, I’m an ex smoker. I smoked for about 5 years, around half a pack a day on average for the last 3 years of smoking, gone cold turkey 8 months ago. The article name is a joke, the only real step you need to do is never smoke another cigarette. Congratulations, you are now an ex smoker. I’ll try to articulate my thoughts about the whole experience, how I started, why I stopped and what kind of impact did it have on my life.
TL;DR version: if you’re smoking you need to stop as soon as humanly possible. It’s hard for some people, it is easy for some – I was fortunate enough to be in the latter group.
Some facts, por favor?
Smoking is not a habit as some like to say. Masturbating before you go to bed is a habit, twirling your hair is a habit, picking your nose in public is a habit. Wikipedia says: “Addiction is a state characterized by compulsive engagement in rewarding stimuli, despite adverse consequences.” Yes, smoking is a full blown addiction just like those alcoholics, crack cocaine users, heroin junkies and so on. Being addicted to nicotine is far more socially acceptable, and up until very recently in our history was practically considered cool. I don’t think I need to go into much detail as how it’s bad for the smoker. The cigarette risk is cumulative and everyone is very prone to dismiss it since it’s relatively harmless in the very short run. You can’t OD on the cigarette, or smoke so much that you’re unable to come in at work in the morning. A lifelong chain smoker can smoke up to a million cigarettes. Try to imagine them all on the floor of your apartment.
Smoking in Croatia is very widespread; it’s allowed in all the bars, pubs, discos, cafes, etc. The estimated numbers in the country are that the third of the adult population are smokers. That number is absolutely devastating for a country which has a modest population of about 4 million and has more than 8000 deaths deaths per year attributed directly to smoking tobacco. Lung cancer was practically unheard of in the medical community before cigarettes were brought en masse to the general public. I realize you have to die of something, and not all cancer can be attributed to smoking. This is one of those very rare times in life where you can avoid a terrible disease easily – by not smoking. Cancer is not the only unwanted side-effect, you can get chronic obstructive pulmonary diseases, cardiovascular issues, etc. The list is pretty long, and as an average smoker you can definitely expect to have a shorter lifespan on average compared to your fellow nonsmoker. It’s not a 100% chance that you’ll develop cancer, or COPD, or whatever. It’s more like around 50% that you’ll have some adverse effects of the constant smoking which will dramatically decrease your quality of life, decrease your lifespan or even die from it before your time. Feel like rolling the dice?
Why smoke & how does the addicted mind work?
Sure, I’ve laid down all the facts, smoking is terrible, smoking is destructive, smoking is expensive. You might ask: “MrKitty, if you’re so smart why did you smoke the 10000-15000 cigarettes, a conservative estimate? Dumbass.” To this, I have no real answer or explanation, other than – I got addicted like all the other poor bastards. What current smokers and never-smokers have to understand, addiction is surprisingly transparent to the addict. I didn’t really comprehend the reality of my addiction until well after I had stopped completely. When you’re a smoker, the cigarette becomes like a natural extension of you. Of course you’re gonna light one up after lunch, at coffee, at a pub, while drinking beer, walking home etc. You find solace in the cigarette, you find companionship as dumb as it sounds. All of this is, of course, complete and utter horseshit. You don’t find anything in the cigarette, other than the need for more cigarettes and more anxiety. You start smoking these things after a while without even getting any kind of a kick. Your body builds up such a tolerance that you basically only replenish the nicotine in your body without the nice feelings it once had brought you.
Ask any smoker why they smoke despite knowing all the bad stuff about the “habit”. You’ll almost always get the answer “Because I get a kick out of it!” They don’t especially like it, they’re trapped in a vicious cycle of maintaining nicotine levels in their bodies. There is no satiating the hunger, it’s almost always there. Taken from http://whyquit.com/pr/122711.html
It’s 3:30AM, the club is almost closed. My smoker friends are all out of cigarettes and I maliciously laugh at them. The last one was shared and smoked between the two of them. They’re so used to the cigarettes with their beers that they’re totally cranky now even though they HAVE JUST SMOKED the last cigarette. So, the club is closing, I finished my beer, I say it’s time to call it a night, I stutter to my bike and I go home. But no, the two of them decide to take a walk to the gas station which is some 2 kilometers away from the club and in the wrong direction from their homes to buy a pack of cigarettes or two, and of course proceed to smoke it. Even though it’s the weekend and 4 AM in the morning, they’ve had busy days and they could have just gone home, but no… they went in the cold and bought cigarettes. Yeah, they’re getting their kick all right. If they ever read this post, they’ll recognize themselves, no hard feelings guys. :)
I know I’m taking the moral high ground now, but in my defense I was never so irrational about this stuff. If the cigs ran out, oh well, they ran out, I’d just buy some more in the morning don’t you worry. The addict rationalizes his addiction by calling it a habit, and claiming it somehow improves their lives and their social life. It does nothing of the sort. I gradually started smoking, it was just a couple of cigarettes here and there, nothing special. Little by little I increased the dosage. The little voice inside me kept telling me that this is wrong, but I somehow didn’t care. Cigarette smoking has a level of self-destructiveness attached to it. At first I’d get sick from the smoking, but I kept on pushing like a brave little soldier. So you get used to them, you buy them as soon as they run out, you can’t imagine drinking a fucking cup of coffee without a cigarette, or a beer. Anything, really, you always find some reason to smoke. You justify and rearrange your whole day to smoke. It is a disaster if you leave the house without the pack and lighter.
How and why did you quit, MrKitty?
In the last months it really started to bother me. I’ve been feeling nauseous a lot of the time, I was feeling physically weak. Nothing that can’t be cured with a cigarette, of course. A friend of mine and his girlfriend came to visit me over one weekend in May. Of course, we smoked, we drank, we went out. That Sunday I had an uneasy ache in my lungs. I felt that I really poisoned myself this time. I saw them out of the building, and bummed a cigarette from my friend while they were waiting for the taxi to take them to the bus station as they were leaving. Wow, that cigarette really didn’t hit the spot. In the elevator ride up I decided, okay, I’m qutting. For reals this time, honest to $DEITY!
I had tried quitting already two years before that. I somehow overestimated myself, I got this shit. I can do it. I’ll just smoke a couple over the weekend with the guys, no big deal. Yeah, that didn’t work out. I held out a couple of weeks and basically continued where I had left off. Not sure what was my rationalization then, but it was apparently enough to keep smoking. The first couple of days were no problem. I had missed the smoking to some extent, but it wasn’t terrible. I noticed how much of my daily routine was revolving around smoking. I suddenly didn’t take smoke breaks with my coworkers. I decided to make a compromise, I’ll continue some of this routine so I’d go out with them to keep them company while refraining from smoking myself. I didn’t rob myself of anything I’d been doing before. I still went out to bars, went out to coffee, beers etc. When I was drunk, I would definitely get the urge. Someone is always smoking, you’re always in temptation to have “just one”. If you’re serious about quitting, you need to buckle down and ride it out. Yeah, you’ll want to smoke, you can’t get rid of it. But sooner or later, you find something, and you’ll start appreciating life more as a non smoker.
I started picturing myself getting sick, having to explain to my now small son why I’m dying of lung cancer or something. You might call that hypochondriacal, but if I go down the line of smoking that is a more likely scenario than I would like to have for myself. Well, I said fuck that! This is something that I’ve been putting off long enough, maybe I should just bite the bullet and ride that shit out. So the days went on by, I had no real cravings during the day. The thought of taking up a smoke was following me like a spectre for some time. My friends that would usually smoke with me had to learn that I don’t smoke anymore. The addiction was strong in me after all, its amazing how it haunted my thoughts, how much time I actually spent thinking about cigarettes. I didn’t want to smoke them, but I was always compelled to think about it, getting all euphoric at times that I’m not a smoker anymore. Like a curse had been lifted from me, I’m finally free.
Pros & Cons, in alphabetical order?
Cons:
None
Pros:
Your taste buds and smells totally awaken. You get used to it, but in the meantime everything smells and tastes delightful. Enjoy it until it becomes the norm. (aprox. 1 – 4 weeks from the last cig)
Your stamina is increased by a lot, unbelievable (a couple of months since stopping)
You start living a different life, I’ll cautiously say, a healthier life. (from the last cigarette until you die)
Financial gain. Cigarettes are expensive, wherever you are, it’s always affordable in the end, but they’re not too cheap.
Too many for this puny bullet list.
E-cigarettes?
While they may be free of the 4000 chemicals the anti-smoking lobby is always mentioning, it’s still nicotine and you don’t want to feed the addiction, get rid of it completely, so you don’t succumb to temptation of having that “just one” real cigarette. I know people that have gone onto the E-cigarette, only to chain smoke a pack or two because they were “stressed”. Newsflash, the stress mostly stems from the fact that you’re going through nicotine withdrawal most of the time, and the E-cigarettes do nothing but pump you full of nicotine and are prolonging your misery.
The industry?
They’re mostly big international conglomerates with a lot of cash flow basically selling us an addictive, expensive, highly dangerous poison. It’s somehow OK, while a little weed is a Problem. I guess the taxation of cigarettes comes in nicely, so everyone is happy. It’s okay not to give these guys money. Here’s a John Oliver video covering it, he’ll say it better than me. Jeff might be sick from all the smoking.
Any conceivable conclusion?
A colleague of mine at work unwittingly gave me the inspiration to really try quitting. He too, was addicted, and doesn’t smoke anymore. So, it can actually be done? Be a non smoker? I’ve browsed through a website called whyquit.com. A relatively weird site, it looks like it came from the nineties, and it probably is. The guy behind it is called Joel Spitzer. He never smoked which is weird when you hear at first. How can he know anything about it? Well, he can, he never smoked and right off the bat he’s better than you, harsh as it sounds. He has an almost evangelistical approach to treating this addiction, and I feel like he’s a good person. It’s hard to say about people like Joel, you get bits and pieces from the distant American culture, but this guy seems all right. He talks about it from a very nice angle. Here is his palmolive bottle demonstartion. He finishes all his videos with “Never take another puff!”
Whether your motivation is the cash influx, or something else it doesn’t matter, it’s hard to give up the drug. Joel says in one of his videos that if you’re going into smoking, you are putting yourself at very real, albeit distant in time risk. Sure, you might live through your life as a two packs a day smoker and die on your 92nd birthday, or you might die from lung cancer at the ripe age of 54. I’ll go with the option that at least precludes lung cancer and a whole palette of nasty ailments. :)
I realize I may come off as a bit sanctimonious, that was never my intention. If you got any smarts, you’ll drop it cold turkey and never look back. Try to lose the nicotine, everyone has got to find their own way. There is no downside to quitting smoking, always keep that in mind. Smokers are addicts and overcoming an addiction is not easy. I bet a lot of people made it their resolution to stop. My only advice is to try cold turkey, convince yourself of whatever you need in order to stay clean.
How am I now?
I don’t think about smoking anymore. I have a lot of smoker friends, they smoke their stuff, I don’t and that’s pretty much it. The memories of me smoking are becoming unreal, have I ever smoked? It left a little bit of emotional scarring I must confess. Not sure why, I’m probably not going to have health issues, but still, it’s unbelievable that I fell victim to such a dangerous, highly addictive substance. At least I learned a valuable lesson from all of this, I managed to get myself addicted and get myself out of it. Perhaps I’ll be more careful next time with something else. In the meantime, I’m watching my son grow older, enjoying time with my lovely wife and generally taking care of myself and enjoying life as much as possible. If I’m not gonna do it, who is?
This post recounts the day when I took a trip with my brother on the 31st of July, 2015. We always had a wish to go to Žirje, just to visit it. It’s located about 22 km southwest from the town of Šibenik, and is pretty much only accessible by ferry or a catamaran. They have regular lines all year.
My brother visits me and my family during the summer, so we get to hang out for a while. This time he brought his bike along with him, so we decided to make it a biking trip to Žirje.
The weather didn’t really inspire a lot of hope, it was an almost overcast sky, with raindrops swiveling around occasionally. Still, we went to buy the tickets, stock up for everything and catch the ferry. On the ferry we proceeded to eat some of the food we had bought earlier. This is a pretty scenic ride actually, and it scenically takes almost 2 hours. But hey, in good company, that’s not so bad. You get a little bit out of your routine, and experience something different whilst stuck on the ferry.
It was windy, but fortunately the clouds were letting up and the day it was actually starting to feel like a regular summer day. Žirje is the furthermost island in the Šibenik archipelago, not counting a tiny island Blitvenica that’s technically even farther than Žirje. This wasn’t my first time taking this ferry to the island. I’ve ridden this exact same ferry at least two or three round trips. I was a part of a crew that was led by the city museum to restore parts of an entrance to an old fortress that’s located on the south-eastern side of the island.
And we’re off.
Never go anywhere without a baseball cap!
Finally we get off the ferry, the last preparations are taking place – it’s time to roll. The island itself is very peaceful as there aren’t that many people around even though the summer tourist season is at its peak. Žirje is populated with people that own houses and live in Šibenik and come to the island during the weekends, a lot of people rent and some people live year-long. There are people outside of the local convenience store that are chugging beers, elderly sitting and chatting. We start biking, first off we have 50 or 60 meters of uphill climb, but this is nothing. The temperature is almost ideal, very few cars around with wind in our hair, we enjoy the island’s serenity.
When I was working on the island the museum rented a small prefab home that is usually used over the summer for tourists. The owner spoke of how they got the home there in one piece on a huge truck that had a crane and simply placed it on the pre-prepared concrete foundations with working power lines, septic disposal, and of course water. We brought our materials on a truck, concrete, lime and sand. We unloaded all of this at the base of the fortress and hired a local man with a 4×4 Ford jeep of some sort. The car was manufactured in the 1940s and was still in working order more or less. The jeep managed to climb the uncomfortably steep rocky path, and it took us about 5-6 trips to get everything near the entrance to the fortress. The path itself was uncomfortable even on foot. Each morning we’d get up, drive to the fortress which was a couple of kilometers away, place some rocks and wait around until 1PM to go back to the house and have lunch that the boss was cooking for us. A pretty sweet deal, and we were getting paid for it too.
The interior of the jeep
We went on to find a beach to take a swim and refresh ourselves. The sea was very warm, and there was absolutely no one around. I’ve not been too many times on a beach that had a body of water that was this clean, translucent, colorful. There were some waves about, and the sea bed was very natural, but this meant very sharp underwater reefs combined with all the perturbations, we had to be careful not to get injured with our bare feet in the lovely sea. After drying up a bit, we changed back to biking clothes and went on to explore the island some more. We had about 6 or 7 ours all in all, so we couldn’t afford to lounge on this wonderful beach for too long. We got on an unpaved road which are plentiful on the island, and are actively maintained by the local population and various civic departments.
We managed to stay clear of all the sea urchins.
You can’t imagine how serene it is.
After some riding we decided it’s time to head out to the fortress. Unfortunately, the fortress itself is completely unmarked on the island, and isn’t really visible almost right until you’re on top of it. Since I was working there for a couple of weeks, I knew where it was. We were cycling on beautiful unpaved roads, with the occasional stop to have some cooled beer we held in our saddle bags. Since it was hot and we were physically active the beers would really hit the spot. We left the bikes where it was appropriate and went ahead to climb the path that the old 4×4 jeep managed to get through. The path was completely unrecognizable. It’s incredible how much vegetation reclaims the area that was cleared away so we can actually go through with the jeep. It’s a 5 minute walk or so, not too steep. The view from the fortress is incredible. You can see the open sea with Italy on the other side of it. Of course the curvature of the Earth is concealing Italy’s mainland. Since the visibility was perfect, various distant islands were just barely visible. Geeks that we are, we have maps on our LG G2’s (we have the exact same phone) and were trying to figure out exactly what island we were seeing.
View towards Italy.
Panoramic view of the only wall left.
This place provides a safe haven to boats, with buoys.
The entrance to the fortress – panoramic.
We took our time on the fortress. I was talking about stories the mason was telling me while we were working there. The man did a lot of archaeological excavations in his time, and this wasn’t my first time working with him. Aside from a big wall, only the foundations of the fortress remain, you can make out the rooms. Incredibly, the fortress had plumbing, and even heating. You can see the canals that were running between the rooms. Fascinating stuff, I can picture in my mind the people that are long dead now that had lives, jobs, responsibilities that were walking around this same place. We’re at least 1500 years apart. Who knows how their workday went on in this fortress. They had names, they had girlfriends, some of them were gay, some of them were unhappy, some of them had love problems, while others were just great and most likely all of them stared at one point or another at the same infinitely straight line of the open sea. The history of the fortress is relatively wacky, as it turns out this particular fortress was built and used at the end of the Byzantine power in the early 6th century century. After Justinian’s death, the funding and supply chain stopped and the fortress was abandoned. It’s estimated that the fortress was operational for 15-20 years, and the fact that no soldier graves were found around the fortress seems to support that. The fortress was one of many that was placed around the Adriatic sea to secure trading lines between Italy and Byzantium.
This place provides a safe haven to boats, with buoys.
I wonder how did this look like when it was operational. I doubt stones were protruding like this, and these sharp weeds were allowed to grow.
The fortress interior.
The fortress interior.
An image of the only remaining wall of the fortress.
The fortress interior. More weeds.
Me + the fortess interior.
Upon leaving the old abandoned military installation we went to the next abandoned military installation on the island. This one is slightly newer, dating back from the Yugoslav People’s Army. It’s located a couple of kilometers of dirt roads and is on a hill, maybe a hundred meters of elevation or so. We braved the hill without stopping, it was pretty steep but luckily paved so it’s that much easier. We actually encountered a car while going uphill. Funnily, the car had New York license plates. These people were from far away. They were probably visiting their ancestors’ homes, as there was a lot of emigration from the island and in general from these areas to the new world at the turn of the 20th century and later. There was a surprising amount of hikers going around the island, mostly foreign people.
The man I was working with was in the army when the base was actually functional and he was serving here. It had a big ass artillery mounted, and some anti-aircraft guns among other things. This was designated to defend against incoming ships, as it was strategically placed. The cannon even had a pivotal role in our own independence war, it was used to shoot at the incoming tanks that were coming in to the Šibenik bridge threatening to attack Šibenik. These were hairy times, and this guy was here when it all happened. The stories about that war are almost always weird and not objective, but this man wasn’t prone telling bs as much as I could gather. The gun, and all of the equipment were stripped away in the nineties after the war was over. You could see only the protruding wires at places. This hasn’t been functional in some time, vegetation is growing all over the place, slowly reclaiming it. Just like the Byzantine fortress.
Selfie without a selfie stick.
This is where the cannon was placed. It had these markers at the base. My guess is to help out with aiming it.
I love these sharp lines on these mini sort of islands.
View from the Yugoslav military base.
We came down from the military base, and went to a road that led to the army barracks. It too is mostly unused, however some people seemed to have establish a place for themselves nearby. The entire walkway between the barracks was completely filled with the stuff that fell from the nearby pine trees. The whole place had a serene quality, the stony floor looked undisturbed for years and years. We took out another beer and a banana, chatted for a while. Suddenly a big dog started barking from the house above. The dog is so used to the solitude, or no one coming near the house that it took some time for him to actually hear us and start barking. This was our cue to leave, apart the incessant barking we were ready to move on. Hunger had started to set in. It was time to find some food, and we were headed back to Muna, that’s where the ferry lands.
Looks like they painted the Croatian flag on top of the old Yugoslav one.
After work and after lunch we’d drink some wine and play cards, or listen to music on the computer. The house didn’t have electricity from the grid, but from solar panels. The panels were basically good enough for some light and to charge our phones – if it wasn’t cloudy during the day. I was texting with my girlfriend a lot, and my coworkers made fun of me for it. We played a lot of chess too, and just talked a lot. They called me Vladimir the invincible since the three of them could never beat me at chess. I’m a below average player, I guess they were even worse than that. During the night we’d set out baits for conger eels, 5 or 6 of them. Most of the time we’d catch something, and sometimes nothing. The nights were great, it was so incredibly quiet. There was no light pollution or pollution of any kind in the air. The center of the Milky Way galaxy was clearly visible, the giant disk of stars, dust, planets, black holes was clearly visible in the sky. The vast distance is difficult to comprehend, and I had a first class view of it. You can never really see it in cities or even smaller settlements because of street lighting. I haven’t had a clear view of the Milky Way ever since then.
The mason was arranging the rocks, while the two of us were mixing up concrete. Not us in the picture, they’re tourists. :)
The eels. The mason on the left, and a friend to the right.
Phycis phycis. Don’t ask, I got it off of google. :)
Worried looks.
Muna is a very small settlement, it has a shop, a ticket shop for the ferry and houses, a restaurant or two. We sat down at one of the restaurants and ordered coffee for starters and asked them for the wifi password. The prices seemed a bit high, so we decided to try our luck elsewhere. We used the wifi to find information about restaurants on the island. There was a restaurant a couple of kilometers away. The reviews of the place were good so we paid for the coffee and left. The restaurant was somehow farther than we had imagined. I ran into two friends from Šibenik. One of the women has a family house there and they were lounging about. It was unusual for me to bump into anyone I know on this island, but it’s not so far fetched since I know she has a house there, but I wasn’t thinking about her the whole time. At last, we found the restaurant, and it was actually open. I went in, Hrvoje followed me a minute later, he was securing the bikes. A woman was eating something at one of the tables, plenty of room for us. The owner’s son approached me and told me he was sorry, but they’re all full and cant’t really feed us. Hrvoje came in and I told him sarcastically that there’s no room for us, even though there’s no one in the restaurant. He further explained that they had an event later on with many guests. We had an hour and a half until the ferry departs. An older man, obviously the owner came and said we could sit down, but the time frame was unrealistic for them to cook us anything. Oh well, we’ll just get something to eat at the store.
A decision was made to go for another swim in front of the restaurant. We had a lot of time on our hands, and Muna isn’t too far away. The sun was slowly setting, but it was still warm. The sea was at an ideal temperature. We jumped, swam and dove a lot. I really wanted to stay some more, but time was slipping away and the ferry wouldn’t wait for us.
Selfie before the last swim.
Even though the sea was basically perfect. I’m not sure what it was, but that’s one of the best times I had at a beach. I’ve been to the beach countless times that summer, but that particular time was simply amazing. The unrelenting passage of time forced us to vacate the pier and start our trek towards the ferry. All this island beauty left us really hungry now. We got into the convenience store to get something to eat. Anything to eat, really. The nice ladies at the shop were sympathetic to our cause, but they had no bread to sell us. One of them must have took pity on us, because she gave us a loaf of bread that was reserved for someone else, but they never showed up. Great, we bought some yogurt, some cheese, some salami and went to the ferry. We got on board and ate it. The entire day of cycling on nothing other than a sandwich at the start of the day, a couple of bananas and some beer. We lounged around the outside deck and watched the flickering lights of the settlements nearby Šibenik. The sun was going down fast.
Riding the ferry back to town.
The atmosphere inside the ferry.
The distant flickering lights of towns in the distance is great to behold.
Everything is sort of slower on islands in general, especially this one since it’s so distant. Žirje is basically dead. I don’t think a lot of people live there, and those that do are elderly. This used to be a bustling port, an island with strategic importance and a population to match. The island is now sparsely populated, and apart from the tourism there’s nothing job-wise. The connection to Šibenik is not all that great which surely plays a role.
The ride back was uneventful. The sun has completely gone down and we’re back in town. The bustling streets, the loads of foreigners walking about the streets. It’s summertime in Šibenik, and it really shows. They bring in hard currency and helps the economy, and it can’t hurt to have a lot of foreign people visiting. Tourism always reflects well for local businesses and practices, it promotes a bit of a metropolitan and urban culture to our small town. Šibenik used to be a powerhouse in terms of various industries, economy, tourism etc. Over the decades Šibenik’s influence and power dwindled, Split and Zadar took over as more important towns. The bike ride to home took another 15 minutes or so. We still had energy. We got something to eat when we got home, and got ready to go to a concert. A legendary Zagreb punk band was coming to Šibenik to play. We were very tired by the time the concert started. The music seemed bland and outright annoying, and the light show was killing me.
It was really time to call it a day around midnight. We came to the concert by car which was parked relatively nearby. I bumped into a couple of more friends. Hrvoje was grumbling that I know a lot of people and bump into someone all the time, and accuses me of spending too much time with each one. I always like to chit chat with people I haven’t seen in a while. You catch up fast, but it takes at least a couple of minutes.
I like the fact that Žirje is so unknown, and that pretty much only locals go there. The island is perfect for biking, and it might even be a better idea to rent something there and stay a couple of days to enjoy it fully. There are no discos there, no fancy restaurants, just the island and its many beaches. I definitely recommend everyone to visit the next time they’re in the area!
This is a picture dump with captions from the trip:
And we’re off.
Never go anywhere without a baseball cap!
The ferry goes to Prvić and Kaprije first. Pictured: Landing in Kaprije
No more stops until Žirje!
This is still Kaprije, I think.
Finally approaching Žirje!
By the side of the road.
We managed to stay clear of all the sea urchins.
Selfie on the bike tracks.
The tracks are marked, and are very pleasent to ride on.
An old timey sign-post for the various places on the island. Not sure how much it’s retro and how much it’s just made to look that way.
You can’t imagine how serene it is.
This is one of the limestone sacks we were hauling from the truck. It broke and we chucked it over a wall so we don’t have to deal with it. I remembered this and took a look 5 years later. The paper sack has completely decomposed, while the lime itself mostly remained the same shape. Not a lot of people go through here, and it was left untouched all this time. It crumbled to the touch.
View towards Italy.
Panoramic view of the only wall left.
This place provides a safe haven to boats, with buoys.
The entrance to the fortress – panoramic.
I wonder how did this look like when it was operational. I doubt stones were protruding like this, and these sharp weeds were allowed to grow.
The fortress interior.
The fortress interior.
An image of the only remaining wall of the fortress.
The fortress interior. More weeds.
Me + the fortess interior.
The breeze was very welcome, and the view incredible.
Selfie without a selfie stick.
This is where the cannon was placed. It had these markers at the base. My guess is to help out with aiming it.
I love these sharp lines on these mini sort of islands.
View from the Yugoslav military base.
Pathway to the barracks.
Looks like they painted the Croatian flag on top of the old Yugoslav one.